
Data Science Tutorial for beginners – This tutorial will help you to kick start your career into Data Science by covering all the core areas from scratch.
Introduction to Data Science
The term “Data Science” is the biggest buzzword from a decade and so, but aren’t new things that we are not aware of. The word “Data Science” has recently emerged, defined, and designed a new profession. “Data Scientist” is a person who keeps and manages vast information of data using data science concepts.
The concept of storing data was from the beginning and is followed by librarians, computer scientists, statisticians, scientists, and others for years. The evolution of the word “Data Science,” the idea of data science and its techniques started a decade ago now. It slowly emerged into real-time applications that we are currently using.
In this Data Science Tutorial, You’ll learn.
- What is Data Science?
- History of Data Science
- Why do we need Data Science?
- Who is Data Scientist?
- Data Science Life Cycle
- Data Science And its Applications
- Big Data and Its Applications
- Data Analytics And Its Applications
- Data Science Tools
- How Does Data Science make working so easy?
- Who can learn Data Science Technologies?
- Data Science Jobs In Today’s IT Market
- Advantages And Disadvantages of Data Analytics
Now continue reading Data Science Tutorial For Beginners
What is Data Science?
Data science is a combination of different tools, algorithms, and machine learning principles with the discovery of hidden patterns from raw data. Data science is about data mining and big data.
History of Data Science – Data Science Tutorial
Even Though data science isn’t a new profession, it has emerged remarkably past 50 years. The concept of data science has begun in early 1962 by a mathematician named John W. Tukey. He forecasted the changes in modern-day electronic computing and data analyzing.
But, the modern usage of data science is quite advanced than the Tukey imagined. Tukey’s forecast was before the explosion of big data and the capability to perform large-scale analysis and complex tasks.
Yet, it wasn’t started until the first desktop computer came into existence in 1964. Till then, any analyses that took place were fundamental to one we are using today.
In 1981, IBM introduced its first PC(Personal Computer). Then very soon, Apple launched its first PC with a graphical user interface (GUI) in the year 1983. During the whole decade, computing started evolving at a faster rate, and allowing the companies to store and collect data more efficiently. However, the conversion of data into up-to-date information has taken nearly two decades.
Why do we need data science?
Data Science is considerably adding value and successfully integrating all the business data, using the concepts of deep learning, and statistics to gain better decision making capability. Data science is also used to predict possible outcomes, risk assessment, and crunch the previous data, etc. so that, we can take measures to avoid them. To set the workflow, an analysis of predicted Data is required.
Who is a data scientist?
A data scientist is a person who can’t stop himself from questioning every new act performed. They are always keen to know the latest changes happening with the data. We can call them a “curious kid.” In the same way, the term data scientist have many shades in terms of work they do. This is the main difference between a statistician, a data scientist, an analyst, and an engineer. The data scientist plays a crucial role compared to other positions, and the task they perform. The purpose of a data scientist depends upon the company and the person, a position may be similar or a mixture of all three (statistician, engineer, and analyst).
DataScience Life Cycle
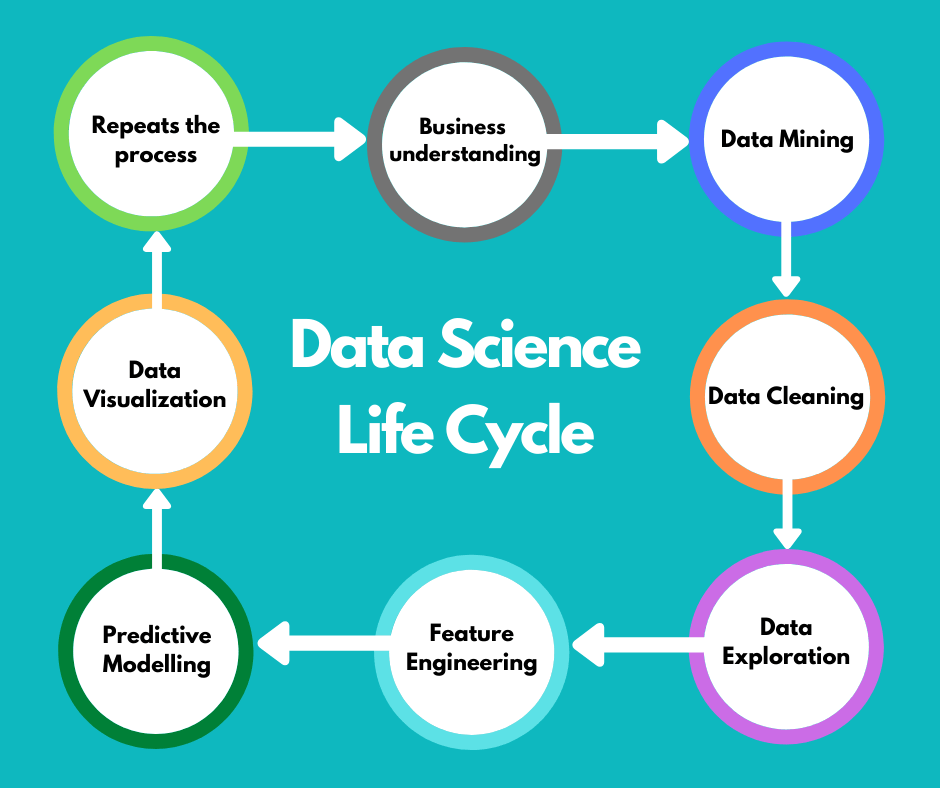
The following are the steps involved in the life cycle of data science(Data Science Tutorial).
1. Business Understanding
In Business-related industries, the role of a data scientist is to ensure every decision that is being taken should have accurate data (strong evidence to prove) that high probability in achieving results. Before you a data science project, the most critical phase is to understand the problem for what is are finding a solution. Following are the five types of questions every data scientist should question himself to find a better solution for the problem
- How much or how many? (regression).
- Which category? (classification).
- Which group? (clustering).
- Is this weird? (anomaly detection).
- Which option should be taken? (recommendation).
In this phase, we should identify the central objective of our project by identifying all the possible variables that are required to be predicted. For example, a sales forecast represents regression. The customer profile represents clustering. The ability to understand the power of data and utilizing it for better results for businesses to expand is an art.
2. Data Mining
After we define the objectives of our project, we need to start gathering relevant data, and the process includes the collection of data from different sources is called “Data mining.” Mining of data can be done either by data retrieval or cleaning and sometimes together.
Firstly we should know how to mine data: for that, we need to know what Data we need for our project, where does it exist, methods to obtain data, and finally, how to store and retrieve data.
3. Data Cleaning
Now, we got all data required for our project, and We proceed to the most critical and time-consuming step – preparing and cleaning the unwanted or irrelevant data. This is the most important reason why it is a time-consuming process. For example, the data could also have inconsistencies, i.e., and the same rows could be labeled with one attribute. Data types inconsistencies like 0s might string in some cases and integers; in other instances, sensitive case inconsistencies might also occur. It’s essential to catch these inconsistencies at this stage and fix them. If we miss correcting or apparent differences, they cause a lot of problems later stages while creating and training the data.
4. Data Exploration
Now, our Data is clean and ready for analysis. This phase is brainstorming. In this stage, we will understand the bias and patterns in our data. It includes: plotting a distribution curve or histogram to view trends, or even creating an interactive visualization and pulling up and analyzing a random subset of the data using Pandas that lets us know in detail about each data set and explore.
Considering all the information, we can now start to assume our data and the methods to tackle our problems. For example, If we are predicting student ranks, we need to visualize the relationship between grades and marks.
5. Feature Engineering
In machine learning (ML), a feature is a measurable property of a phenomenon that is being observed. For example, In complex prediction tasks like character recognition, the feature could be histogram counting the number of white pixels. The functions require expert knowledge as they are involved.
Definition:
“Feature engineering” is the method of using domain knowledge to change our unstructured data into informative features that represent our problem that we are trying to solve. This phase will influence the accuracy of the predictive model that we construct in the next phase.
The following are the two types of tasks that we perform in feature engineering:
Feature selection
The process of removing the features that cause noise rather than information. We do this to avoid the complexity that arises from high-dimensional spaces (too many features). But, we generally use methods to avoid noise from data. Following are methods to remove noise from data:
- Filter methods.
- Wrapper methods
- Embedded methods
Filter methods: In this method, we apply statistical measures and assign scoring to all features individually.
Wrapper methods: By this method, we frame the selection of features like a search problem and use a heuristic to perform the search.
Embedded methods: we use machine learning algorithms to find which features suit our problem that can provide accurate results.
Feature construction
This task involves creating new features from the existing features. This task is performed when we continuous change in input variables, and we need an indicator variable of known value as a threshold to check. For instance, if we have a feature for age, but our prototype wants to check whether a person is a minor or an adult, we could see the threshold age at 18, and assign different feature for below and above that threshold.
6. Predictive Modeling
Finally, this the phase where machine learning comes picture where the concept of predictive modeling is used in our data science project. Based on the questions we asked in the business understanding phase, this is where we decide and pick the right prototype that suits our project, and to decide the right prototype is always a difficult task when there are multiple right solutions.
7. Data Visualization
This is the most tricky phase in the data science life cycle. It looks simple but, one of the hardest things too because data obtained is a combination of different fields like statistics, communication, art, psychology, etc. The goal is to communicate the data in an effective, visually pleasing and in a simple way. Once we obtain the required insights from our prototype, we need to represent them properly so that various customers in the project should understand.
8. Business Understanding
Now, we will get back to the first stage of the lifecycle as it is an iterative process. This the final evaluation phase to know how successful we have completed our project. Our model should be able to answer the following questions:
- Does the model tackle the problems identified?
- Does the analysis yield any relevant solution?
If we encounter any new insights while the first iteration of the lifecycle, we can now include them and continue the next iteration, this process continues until the exact answer to the problem is found.
Data Science and its applications – Data Science Tutorial
Data Science Tutorial (Applications): Is a method of dealing with structured and unstructured data. It is a field that performs data analysis, preparation, and cleansing. It is an integration of aligning the data, statistics, preparing, problem-solving, mathematics, the ability to capture data in a clever way, view it differently, and clean up activities, and programming. These are the techniques used when we try to extract information and insights from data.
The following are the areas where data science is used
- Digital Advertisements
- Internet search
- Recommender systems
Digital Advertisements
The latest trend of digital marketing makes use of data science algorithms. Right from digital billboards to display banners, data science techniques are used. This is the important reason why digital ads are getting a higher rate (CTR) than regular advertisements.
Internet search
Search engines like google make use of these algorithms to give the best results for a query in seconds.
Recommender systems
This system makes the search process easy and to find relevant products(searches) from trillions of data available. It provides a user-friendly experience. Many organizations use the recommender system for suggestions and also promote their products according to user demands and relevant searches. Based on the uses, results in recommendations are suggested.
Big Data and its applications – Data Science Tutorial
Big Data represents huge volumes of data that cannot be processed accurately with the traditional applications that previously exist. The processing of Big Data starts with the raw data that isn’t integrated and often impossible to store in the memory of one computer.
A frequently used word to represent huge volumes of data that is structured and unstructured is Big Data. Big Data overwhelmed the business day by day. It can be used to analyze trends that help in making better decisions and strategic moves related to business.
Gartner defines Big Data as, Big data is a high capacity, high speed, and/or high variety of information assets that require cost-effective, innovative forms of information processing that enhance insight, decision-making, and process automation..”
Data Science Tutorial: Applications of Big Data
Big Data for financial services: Big Data is implemented in many firms like private wealth management advisories, venture funds, institutional investment banks, retail banks, insurance firms, and credit card companies that use big data for their financial services.
The most prevailing problem with the massive amounts of data which is both structured and unstructured data (multi-structured) across multiple systems can be solved by big data techniques. This the reason why big data is used in many ways like Customer Analytics, Compliance Analytics, Fraud Analytics, and Operational analytics.
Data Analytics and its applications
Data Analytics is the method to examine raw data to obtain conclusions about that information analyzed. It involves the application of a mechanical process to derive insights and algorithms. For instance, it is identifying meaningful relations by checking various data sets between each other.
Data Analytics widely used across many industries to allow the enterprise to make better decisions, verify and disprove previous models. Data Analytics always focuses on obtaining conclusions completely based on research. The following are some of the industries where data analytics play a major role:
- Travel
- Energy Management
- Healthcare
- Gaming
Travel
Through the social media data analysis, and the mobile or weblog data optimize the shopping experience. For instance, a travel site will be aware of the customer’s preferences and desires based on their previous search results. By this, companies can promote their products based on their frequent searches and customized packages according to customers’ preferences. Data analytics provides these personalized travel recommendations based on social media data.
Energy Management
Data analytics are used in many organizations for energy optimization, energy management, building automation, energy distribution, and including smart-grid management in small firms. The application is used to monitor and control the network devices, manage service outages, and dispatch crews.
Healthcare
The complex task for hospitals is to maintain the records of the patient undergoing or underwent treatment in their hospitals. So, to improve the quality of care must be taken in maintaining proper records. To track and optimize patient flow, equipment used in the hospitals, and treatment-related information instrument and machine data are widely used.
Gaming
It helps in collecting data to optimize various games. Gaming organizations gain insights for the likes, dislikes, and the relationship of the user.
Data Science Tutorial: Data Science Tools
R Programming
“R” one of the leading analytics tools widely in industries for data modeling and statistics. It manipulates Data and present in many ways. R can be compiled and run on any OS platforms like Linux, UNIX, Windows, Ubuntu, and Mac OS. It has around 11,556 packages, and one can browse these packages by category. R tools automatically install all packages according to user requirements.
Python
It is an object-oriented scripting language. It is a free open source tool easy to read, write, maintain. Guido van Rossum developed it in the 1980s that supports both structured and functional programming is very similar to JavaScript (js), Ruby, and PHP and is easy to learn. Also, it has useful machine learning libraries like Tensorflow, Keras, Theano, and Scikit Learn another essential feature of Python is: it can be assembled on any database platform viz JSON, SQL server, and a MongoDB database.
Tableau Public
Tableau Public connects any data source that might be Microsoft Excel, web-based data, and corporate Data Warehouse that creates dashboards, data visualizations, maps, etc. with real-time updates on the web. The main advantage of Tableau Public is that it is a free (open) software. This can be shared with clients and through social media.
Apache Spark
Berkeley’s developed Apache in 2009. It is a fast large-scale data processing engine that can execute applications in Hadoop clusters. Apache Spark 10 times faster on disk operations and aster in-memory operations. Spark is built on concepts of data science, and its techniques make data science easy. Spark is one of the most important and popular tools for machine learning models and data pipeline development. Spark also includes machine algorithms for repetitive data science methods like Regression, Classification, Filtering, Collaborative, and Clustering.
SAS
Sas is a leader in analytics and is a programming environment where data can be manipulated. It was developed by the SAS Institute in 1966 and further developed in the 1980s and 1990s. SAS is a flexible, easily accessible tool that can analyze data from various sources. SAS modules for marketing, web, and social media analytics are widely used for prospects and profiling consumers. SAS can predict behaviors, manage, and optimize communications.
RapidMiner
It an integrated data science platform developed by RapidMiner that performs the predictive analysis. It can also perform advanced analytics like machine learning, data mining, visual analytics, and text analytics without programming. RapidMiner can be incorporated with any data source, including Excel, Tera data, Dbase, Oracle, Microsoft SQL, Sybase, Ingres, MySQL, IBM SPSS, IBM DB2, etc. RapidMiner is very powerful and can generate analytics based on real-life data.
Splunk
Splunk is a tool that can search and analyze the data generated by machines. It pulls all text log data and provides an easy way to search through it.
KNIME
KNIME Developed in January 2004 by a software engineer at the University of Konstanz. It is leading integrated analytics tools, open-source, and reporting that allow to analyze and model the data through visual programming, it combines various components form machine learning and data mining through its modular data pipelining concept.
QlikView
QlikView has a unique feature like in-memory data processing, and patented technology, which executes the results quickly to the end-users and stores the data in the form of reports. The feature, like data association in QlikView, automatically maintains and compresses data to almost 10% from its actual size. Data relationship is represented using colors – if the same color is assigned to related particular data and another color for unrelated data.
Excel
Excel is the most popular and essential analytical tool widely used in every enterprise. Even if you’re an expert in R, Sas, or Tableau, you still have to use Excel. Excel plays a major role when there is a need for analytics on the client’s side. It analyzes and summarizes the complex tasks preview of data on pivot tables to filter the data as per client requirements.
How does Data Science make working so easy? – Data Science Tutorial
The applications that we are currently using to fulfill our day-to-day needs are made simple and user-friendly using data science concepts. For example, All the online shopping websites and apps such as Flipkart, Amazon, etc. have searched for watches and found advertisements related to your search on the apps or websites continuously for a week, Or while chatting the prediction on your keyboard suggests you the next word you wanted to use in your sentence?. The YouTube show suggestions and all your subscribed on your home screen.
All this is because of data science techniques. These are all some of the applications of Data Science. Past few years Data Science has really changed our perception of technology. Our lifestyle has changed, and it has been easier compared to the last ten years. This all possible because of data science. Data science is being used everywhere right from social media applications like Facebook, Twitter, LinkedIn to Tinder. Data Science has pulled the edge between technology and fiction.
These are some of the business applications of Data Science. Very soon, data science is going to be the core of the digital world. Can we imagine ourselves without the facilities that we are currently habituated to? But we need to know that Data Science makes our lives as easier as possible. Soon, the transformation in Data Science can create miracles not only in technology but can perform a medical operation without a doctor.
Who can learn Data Science technologies?
Based on one’s interest, anybody can learn data science. Persons with strong educational background, good statistics, and mathematical knowledge and reasonably good programming skills can become a good Data Scientist. These are some of the prerequisites required to master data science.
- Knowledge of any coding language like Python, Perl, Ruby, etc. Which are the most often used coding languages.
- knowledge of SAS or R programming.
- SQL database coding.
- Should have command on statistics like rank, median, etc.
- Knowledge of Machine learning is required.
SCOPE :
Data Science has a bright future, as many industries adopt these methods to analyze huge data. There are many companies that hire Data Scientists as they are the future hope:
E-commerce: club factory, Amazon, Flipkart, etc.
Service-based analytics company: Mu-Sigma, Vizury, Fractal Analytics, Impetus, TCS…
Startups: Housing, Ola, cabs, Uber, etc.
Product-based MNCs: Microsoft, IBM, Accenture all the other top enterprises are in need of data scientists.
Payment for data scientist depends on various factors listed below:
Company.
Experience.
Negotiation at the time of the interview.
Data Science Jobs
By studying data science, you can find a variety of fascinating responsibilities in this area. The main responsibilities & job responsibilities are as follows:
- Data Scientist
- Data Analyst
- Data engineer
- Machine learning expert
- Data Architect
- Data Administrator
- Business Intelligence Manager
- Business Analyst
Data Scientist:
Data scientists are professionals who process large amounts of data and deploy with a variety of tools, technologies, methods, algorithms, and more to gain compelling business insights.
The skills required: To become a data scientist, you must have technical language skills such as R, SAS, Apache Spark, SQL, Hive, Python, Pig, and MATLAB. Data scientists must understand the statistical, mathematical, visual, and communication skills.
Data Analyst:
A data analyst is an individual who performs a large amount of data mining, models data, finds patterns, relationships, trends, and so on. Finally, he proposes visualizations and reports to analyze data in a decision-making and problem-solving processes.
Skills Required: To be a data analyst, you need to make good use of the basics of math, business intelligence, data mining, and statistics. You should also be familiar with computer languages and tools such as Python, MATLAB, SQL, Pig, Hive, SAS, Excel, R, Spark, and JS.
Data Engineer:
Data engineers process large amounts of data and are responsible for building and maintaining the data architecture for data science projects. Data engineers are also working on creating dataset processes for modeling, mining, retrieval, and validation.
The skill required: Data engineers must gain insight into languages such as SQL, Cassandra, Apache Spark, MongoDB, HBase, Python, Honeycomb, C/C, Java, MapReduce, and Perl.
Machine Learning Experts
Machine learning experts are people who use a variety of machine learning algorithms used in data science, such as regression, clustering, classification, decision trees, and random forests.
The skill required: Computer programming languages such as C++, Python, R, Hadoop, and Java. You also need to understand a variety of algorithms, analytical skills, probabilities, and statistics for problem-solving.
Data Architects
Data architects build and maintain enterprise databases by identifying structures and installation solutions. Work with database administrators and analysts to easily access company data.
The skill required: Required Strong knowledge of data structures and DataMining, Good Communication skills.
Advantages of Data Analytics – Data Science Tutorial
Following are the advantages of Data Analytics:
- Data cleansing is the complete process of identifying and correcting the errors from data sets. This aids in the quality of data and simultaneously benefits both institutions and customers.
- Examples of finance companies, banks, and insurance corporations.
- The CTC (the cost to company) is reduced by data analytics as they clean the redundant data from the database and save huge memory space.
- Machine learning algorithms are used to display relevant advertisements on online shopping Apps or websites. These ads are based on users’ purchase-behavior and search history, and Therefore they indirectly increase their sales, productivity and overall revenue of the company.
- Data science acts as a fraud detector by identifying fraudulent customers based on analyzing the previous data and reduce the risk of online banking through credit or debit card.
- The security agencies use them for monitoring and surveillance purpose based on information collected by several sensors.
Disadvantages of Data Analytics
Following are the disadvantages of Data Analytics:
- Data science may have the possibility of crack the privacy of the customers by stealing information related to online transactions, purchase history, subscriptions that are visible to the companies. There might be a chance of misuse of customer databases by companies for their mutual benefits.
- The data analytics tools differ based on the features or applications that it supports. Firstly, some of the data analytics tools are difficult to use without proper training. Secondly, CTC (the cost to the company ) to implement data analytics software or tools is costly.
- The information can be misused among a group of people, caste, or a community.
- It is always complex to choose the right tool to analyze data because it requires fact data sets or knowledge to improve their accuracy in analyzing the data according to relevant applications.
- Data analytics is not time and cost-effective.
End points of Data Science Tutorial
More than six years now, data science is one such technology that is constantly evolving by making its roots stronger. Data science has spread to nearly every industry that relies on or generates data.
In recent years, data scientists are more important and highly valued employees of any company. Organizations are ready to pay dollars to hire them, and many data science degrees and pg programs have emerged from training and certifying the new generation of data scientists. Data scientists are hired from various educational backgrounds such as psychology, computer science, and health information management.
The usage of data science and its applications will keep on growing day-by-day as data will become even bigger. For example, 90 percent of Indians are using cell phones, and huge amounts of data produced each day. According to the “Pew Research Center” Nearly eight in ten Indian adults have their own laptops or desktop computers. More than 50 percent of the people have their own tabs and other Ipads. Seventy-eight percent of the people are health conscious and are willing to track their daily working schedules.
Data science is just now flourishing, and with roots deep down, in the next ten years, data science is going to play a major role, and the entire world will be different thereafter.
Hope you enjoyed this Data Science Tutorial. If you find any information useful and missed in this Data Science Tutorial, Please leave us your valuable comments in the section below. Thank You…
Make Learning Simple By Learning Technology Form Scratch



nice information , thanks for sharing
Thank you for sharing the information